GPT-5.5で古いプロンプトを見直すべき理由——OpenAI公式が示す7要素構造とゼロから組み直す戦略
はじめに
2026年4月、OpenAI は GPT-5.5 のリリースに合わせて公式ドキュメント 「Prompt guidance」 および 「Using GPT-5.5」 を整備しました。そこで明確に打ち出されたのが、「古いプロンプト技法を持ち越すな(avoid carrying over every instruction from an older prompt stack)」という指針です。
「ステップ・バイ・ステップで考えて」や ALWAYS / NEVER の乱用といった、これまでベストプラクティスとされてきた技法の 多くのケースで効果が薄れる、あるいはノイズとして働く ことが公式に整理されました。
この記事のポイント
- OpenAI 公式が「古いプロンプトを持ち越さず、ゼロから組み直す」ことを推奨
- 多くのタスクで見直し対象となるのは、思考過程の明示的な誘導・絶対命令の乱用・過剰な役割演出・微細なプロセス管理など
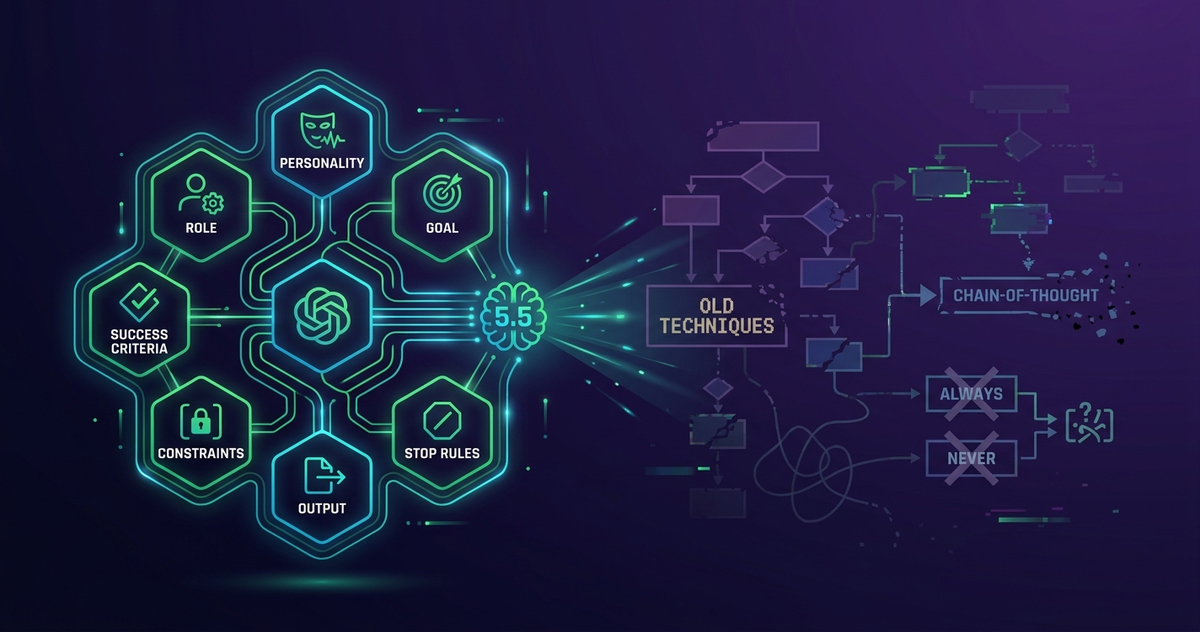
- 推奨は「役割(Role)→ 人柄(Personality)→ 目的(Goal)→ 成功基準(Success Criteria)→ 制約(Constraints)→ 出力(Output)→ 停止条件(Stop Rules)」の 7 要素構造
OpenAI のプロンプト指針はなぜ転換したのか?
GPT-5.5 は推論をより効率的に行えるため、人間が「考え方」を細かく教える従来型プロンプトが過剰指示として作用しやすくなった のが背景です。OpenAI 公式ガイドは「旧来のプロンプトは古いモデルが軌道を維持するための補助としてプロセスを過剰指定している」("Legacy prompts often over-specify the process because earlier models needed more help staying on track.")と明記しています。
The Decoder の解説(2026年4月26日)も、古いプロンプトは「ノイズを生成し、モデルの探索空間を狭め、機械的な回答を産出する」と整理。ビジネス+IT の解説記事(2026年4月28日)でも、プロセス(手順)中心から成果(アウトカム)中心への転換 がポイントだとまとめています。
GPT-3.5 や GPT-4 時代に「魔法の呪文」として効いた多くのテクニックは、GPT-5.5 では文脈次第で効きにくくなる、というのが今回の指針の核心です。
どんな古いテクニックが見直し対象になるのか?
OpenAI 公式(Prompt guidance / Using GPT-5.5)と各種解説記事を踏まえると、見直し対象は次のような技法群に整理できます。「常に逆効果」ではなく、多くのタスクで効きが悪くなる・過剰指示として働きやすい という位置づけです。
① 「ステップ・バイ・ステップで考えて」系の思考過程の明示誘導
連鎖的な思考過程(chain-of-thought)の明示的な誘導は、GPT-5.5 では 多くのタスクでモデルの探索空間を不必要に狭めます。手順そのものが要件である場合は依然として有効ですが、汎用的な「ステップ・バイ・ステップで考えて」の付与は、GPT-5.5 が内部で行う推論を上書きしてしまうため過剰指示になりがちです。
② ALWAYS / NEVER などの絶対命令の乱用
OpenAI 公式は「不必要な絶対ルールを避けよ。古いプロンプトはモデルの挙動を制御するために ALWAYS、NEVER、must、only などの厳密な命令を使いがちだ」("Avoid unnecessary absolute rules. Older prompts often use strict instructions like ALWAYS, NEVER, must, and only to control model behavior.")と述べています。絶対命令は安全要件・必須出力フィールド・本当にやってはいけない行為など、真の不変条件にだけ使うべき という指針です。判断が必要な場面で乱発すると、制約同士が衝突し出力が破綻します。
③ 過剰な役割演出(ロールプレイの肉付け)
「あなたは世界最高峰の○○エキスパートです」「深呼吸して」「論理的に分析して」といった、性能向上を目的としたロールプレイの肉付け は GPT-5.5 では効果が薄く、応答を不自然にすることがあります。OpenAI の推奨構造では、役割(モデルの職務・文脈)と人柄(口調・協働スタイル)は別セクションで整理し、誇張した役割演出は避けるのが基本です。
④ 「念のため」貼った例示プロンプト(数例提示)
数件の例を貼り付けて期待出力を固定する手法(いわゆる few-shot)は、独自フォーマット指定など本当に必要なときには有効ですが、「念のため」貼った例は出力の多様性を奪い、例に過剰適合させる 危険があります。ビジネス+IT の解説でも「不必要な例示」がリスクとして指摘されています。成功基準や出力仕様で意図を伝えられないかをまず検討するのが安全です。
⑤ 微細なプロセス管理(マイクロマネジメント)
「必ず 5 段階で分析し、各段階で 3 つの観点を列挙せよ」のような 詳細な手順指定 は、モデルの自律的な判断を奪います。OpenAI ガイドは「道のりよりも目的地を描け」("describe the destination rather than every step")と表現しています。手順そのものが要件の場合は明示する、それ以外は成果と成功条件で代用するのが指針です。
OpenAI が推奨する 7 要素構造とは何か?
GPT-5.5 で OpenAI が推奨するのは、手順ではなく 成果(アウトカム)を中心に据えた 7 要素構造 です。
| 要素 | 中身 | 記述例 |
|---|---|---|
| 役割(Role) | モデルが担う立場 | "顧客サポート担当者" |
| 人柄(Personality) | 口調・協働スタイル | "簡潔で丁寧、ビジネスライク" |
| 目的(Goal) | 達成すべき結果 | "返品リクエストを最後まで解決する" |
| 成功基準(Success Criteria) | 完了の判定軸 | "返品可否が判断され、可能なアクションが完了している" |
| 制約(Constraints) | 法律・セキュリティ要件 | "個人情報を平文で出力しない" |
| 出力(Output) | 成果物の形式 | "3〜6 文 または最大 5 項目の箇条書き" |
| 停止条件(Stop Rules) | 中止条件 | "情報不足時は明示的に質問する" |
前者 4 つで「何を達成するか」を、後者 3 つで「どこまで・どう出すか」を縛る 構造です。OpenAI 公式の Before(避けるべき)/After(推奨)を要旨化すると、対比は次のようになります(実際の公式テキストはより詳細で、ツール呼び出しやデータ参照、欠損情報のハンドリングまで含みます)。
# Before(避けるべき/要旨)
First inspect A, then inspect B, then compare every field,
then think through all possible exceptions,
then decide which tool to call.
# After(推奨/要旨)
Resolve the customer's issue end to end.
Success means: the eligibility decision is made from available data;
any allowed action is completed;
final answer includes completed_actions, customer_message, and blockers.手順を書かない代わりに、何が「完了」かを定義する——これが新世代プロンプトの核心です。完全な公式文は Prompt guidance を参照してください。
既存プロンプトをどう移行すればいいのか?
OpenAI は 「ゼロから組み直せ(fresh baseline で始めよ)」 と明確に推奨しています。既存の GPT-4 / GPT-5 用プロンプトをそのまま GPT-5.5 に投入するのではなく、最小プロンプトから組み直すアプローチです。
実務的な移行ステップは次の通りです。
- 既存プロンプトを全削除し、目的(Goal)と成功基準(Success Criteria)だけ残す ところから始める
- 出力が逸脱する場合のみ制約(Constraints)を追加(不変条件のみ)
- 出力形式が不安定なら出力(Output)仕様を厳密化("3–6 sentences or ≤5 bullets" 等)
- ツール呼び出しが暴走するなら停止条件(Stop Rules)を追加("Can I answer the user's core request now?" のチェック)
reasoning_effortを明示設定(GPT-5.5 のデフォルトはmedium。GPT-5.2 系はnoneがデフォルトのため、移行時は混同しない)
ZenChAIne でも社内の AI エージェント実装で同様の移行を進めており、特に 出力仕様を厳密に書くだけで応答品質が大きく安定する という感触があります。冗長な役割演出や手順指示を削った分、トークンコストとレイテンシも下がります。
よくある質問
Q. すべての連鎖的思考の指示が悪いのですか?
A. いいえ。OpenAI の指針は 「多くのタスクでは手順を書くより成功条件を書け」 という条件付きで、手順そのものが要件である場合は明示してよい とされています。複雑な推論が必要なら reasoning_effort を medium 以上にすればモデル側がより深い推論を内部的に使うので、明示的な「ステップ・バイ・ステップで考えて」を毎回書く必要はないというだけです。
Q. ALWAYS / NEVER は絶対に使ってはいけませんか?
A. 真の不変条件には使うべきです。たとえば「個人情報を出力しない」「特定の API キーをログしない」「禁止カテゴリの出力を行わない」など、安全・コンプライアンス上の絶対要件 には ALWAYS / NEVER が適切です。判断の余地があるルールには使わない、というのが指針です。
Q. 例示プロンプト(few-shot)は完全に廃止ですか?
A. 廃止ではありません。成功基準だけでは伝わりにくい独自フォーマットや特殊な領域 では引き続き有効です。ただしビジネス+IT の解説でも指摘される通り、「念のため貼っておく」例は出力の多様性を奪うリスクがあるので、本当に必要な場合だけ最小限(1〜3 件)にとどめるのが推奨です。
Q. GPT-5.5 で reasoning_effort はどう設定すべきですか?
A. GPT-5.5 のデフォルトは medium です。OpenAI 公式ガイド「Using GPT-5.5」でもこれが推奨開始点として示されています。レイテンシ重視なら low を評価し、none は推論や複数ツール呼び出しが不要な軽量タスクに限定します。GPT-5.2 系のデフォルトは none ですが、これと混同しないよう注意してください。OpenAI は 「モデルと effort を固定してから評価(evals)を回し、品質後退が起きた場合にだけ effort を上げる」 という段階的調整を推奨しています。
Q. 既存のプロンプトはすぐ書き換えるべきですか?
A. 本番運用で問題が出ていない場合は、急ぐ必要はありません。ただし新規開発や品質改善のタイミングで ゼロから組み直す のが効率的です。OpenAI は「都度書き換える」より「ベースラインから再構築」を勧めています。
まとめ
GPT-5.5 のプロンプト設計は、手順中心から成果中心への転換 を要求しています。「ステップ・バイ・ステップで考えて」「ALWAYS / NEVER の乱用」「過剰な役割演出」「念のための例示プロンプト」「微細なプロセス管理」——これらは多くのタスクで効果が薄れる、あるいは過剰指示として作用するというのが OpenAI の整理です(手順そのものが要件である場合は依然として明示してよい)。
代わりに OpenAI が推奨するのは、役割・人柄・目的・成功基準・制約・出力・停止条件の 7 要素構造 と、ゼロから組み直す移行戦略 です。プロンプトを書く側の心構えとして、「どのように」ではなく「何を達成するか」を定義する姿勢が鍵になります。
ZenChAIne でも GPT-5.5 を前提にした社内エージェント・クライアント実装の移行を進めており、引き続き実務知見を発信していきます。