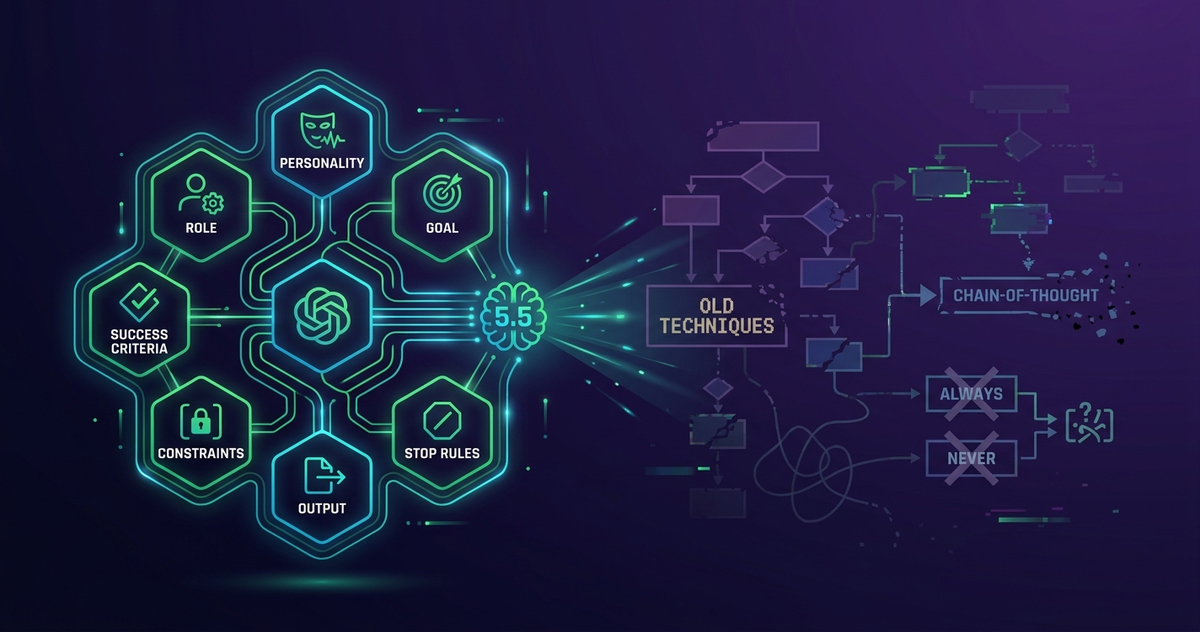
Why Old Prompts Hurt GPT-5.5: OpenAI's 7-Element Structure and the Fresh Baseline Strategy
Introduction
In April 2026, OpenAI shipped its official Prompt guidance and Using GPT-5.5 documentation alongside the GPT-5.5 release. The headline directive is striking: "avoid carrying over every instruction from an older prompt stack."
OpenAI flags process-heavy prompting — chain-of-thought nudges, ALWAYS/NEVER directives, heavy role-play scaffolding, granular process control — as noise that narrows the model's search space and produces mechanical answers in many tasks (the guidance is condition-aware, not a blanket ban). Business+IT additionally warns that "just-in-case" few-shot example dumps fall in the same overspecification trap.
Key takeaways
- OpenAI explicitly recommends rebuilding from a fresh baseline rather than carrying GPT-4-era prompt stacks into GPT-5.5
- For many tasks, the techniques to revisit are CoT nudges, overuse of absolute rules, heavy role-play scaffolds, and granular process control
- The recommended replacement is a 7-element structure: Role → Personality → Goal → Success Criteria → Constraints → Output → Stop Rules
Why has OpenAI's prompting philosophy shifted?
GPT-5.5 reasons more efficiently than its predecessors, so manually scripted "thinking steps" now tend to act as friction rather than scaffolding. The official guide states: "Legacy prompts often over-specify the process because earlier models needed more help staying on track."
The Decoder's coverage (April 26, 2026) summarizes this as legacy prompts "generating noise, narrowing the model's search space, and producing mechanical answers." The shift is from process-centric to outcome-centric prompting — describing the destination rather than every turn along the way.
Many "magic spells" from the GPT-3.5/GPT-4 era are no longer load-bearing on GPT-5.5 — they often work against you when the task doesn't actually require a fixed path.
Which legacy techniques become counterproductive?
OpenAI's official guidance and accompanying analyses point to several technique families that warrant a rethink. The framing is "counterproductive in many cases" rather than universally banned — when a fixed procedure is part of the requirement, you should still spell it out.
1. Chain-of-thought nudges like "think step by step"
Explicit CoT prompting was the GPT-4 default but constrains GPT-5.5's search space unnecessarily for many tasks. When the procedure itself is part of the requirement, an ordered list still helps; otherwise, blanket "step by step" instructions tend to override the path the model would have chosen.
2. Overuse of absolute rules (ALWAYS / NEVER)
OpenAI explicitly states: "Avoid unnecessary absolute rules. Older prompts often use strict instructions like ALWAYS, NEVER, must, and only to control model behavior." Reserve those for true invariants — safety rules, required output fields, hard prohibitions — not for judgment calls. Stacking absolutes on judgment-heavy tasks causes constraint collisions and broken outputs.
3. Excessive role-play scaffolding
Patterns like "You are the world's leading expert in...", "take a deep breath", or "think logically" — performance-boosting scaffolds from earlier eras — often stop helping on GPT-5.5 and can make responses sound mechanical. In OpenAI's recommended structure, Role (the model's job and context) and Personality (tone and collaboration style) live in separate sections; that separation, plus dropping the pep talk, is the recommended replacement.
4. "Just-in-case" few-shot examples
Pasting a handful of examples is still useful for genuinely unusual formats. The risk flagged by Business+IT is the "just-in-case" few-shot dump that flattens output diversity and over-fits to the examples — for routine cases, explicit Success Criteria and an Output spec usually do more work, more cheaply.
5. Micro-managing the process
Highly granular process control like "first analyze in 5 stages, listing 3 perspectives at each stage" strips away the model's autonomous judgment. The OpenAI guide phrases it well: "describe the destination rather than every step." Spell out the procedure when the procedure is the requirement; otherwise, swap it for an outcome and a clear definition of done.
What does OpenAI's 7-element structure look like?
OpenAI's recommended structure for GPT-5.5 places outcomes at the center and orders prompt elements as follows.
| Element | Role | Example |
|---|---|---|
| Role | The model's stance | "Customer support agent" |
| Personality | Tone and demeanor | "Concise, polite, business-like" |
| Goal | The outcome to deliver | "Resolve the return request end to end" |
| Success Criteria | Definition of done | "Eligibility decided from available data; allowed actions completed" |
| Constraints | Legal / security requirements | "Never output PII in plaintext" |
| Output | Format of the deliverable | "3–6 sentences or ≤5 bullet points" |
| Stop Rules | When to halt | "Ask explicitly when information is missing" |
The first four elements lock in what to deliver; the last three constrain how and how far. The Before/After contrast below is a paraphrase of OpenAI's canonical example — the actual published text is more detailed, including tool-call wording, data references, and how to handle missing evidence (see Prompt guidance for the full version).
# Before (avoid — paraphrased)
First inspect A, then inspect B, then compare every field,
then think through all possible exceptions,
then decide which tool to call.
# After (recommended — paraphrased)
Resolve the customer's issue end to end.
Success means: the eligibility decision is made from available data;
any allowed action is completed;
final answer includes completed_actions, customer_message, and blockers.Don't write the process — define what "done" means. That is the heart of next-generation prompting.
How should you migrate existing prompts?
OpenAI's clear recommendation is to start from a fresh baseline rather than mutating GPT-4-era prompts in place. Practically:
- Strip everything down to Goal and Success Criteria as a starting point
- Add Constraints only when output drifts — and only for true invariants
- Tighten Output spec when format is unstable (e.g., "3–6 sentences or ≤5 bullets")
- Add Stop Rules when tool use spirals (e.g., "Can I answer the user's core request now?")
- Set
reasoning_effortexplicitly — GPT-5.5 defaults tomediumper the official "Using GPT-5.5" guide; the GPT-5.2 family defaults tonone, so do not conflate the two
At ZenChAIne we've taken the same approach for our internal agent stack, and the most consistent win has been tightening the Output spec — response quality stabilizes dramatically, and dropping the scaffolding lowers token cost and latency at the same time.
FAQ
Q. Is all chain-of-thought bad now?
A. No. The guidance is "prefer outcomes and success criteria over hand-scripted procedures for many tasks" — and when a fixed procedure is itself the requirement, you should still spell it out. For genuinely complex reasoning, raising reasoning_effort to medium or high lets the model use deeper reasoning internally; you simply don't need to write "think step by step" everywhere.
Q. Should ALWAYS and NEVER never appear in prompts?
A. Use them for true invariants only: "Never output PII", "Never log specific API keys", "Never produce content from prohibited categories". For anything that requires judgment, drop the absolutes.
Q. Is few-shot prompting fully deprecated?
A. No. For unusual formats or domains where Success Criteria alone are hard to specify, few-shot still helps. Business+IT specifically flags the risk of "just-in-case" example dumps — keep examples minimal (1–3) and only when truly necessary.
Q. How should I set reasoning_effort on GPT-5.5?
A. GPT-5.5 defaults to medium, per OpenAI's "Using GPT-5.5" guide — that's the recommended starting point. Drop to low if latency matters; reserve none for lightweight tasks that don't need reasoning or multiple tool calls. The GPT-5.2 family defaults to none, so don't carry that over. OpenAI recommends fixing the model and effort, running evals, and bumping effort up only on regressions.
Q. Should I rewrite all my existing prompts immediately?
A. Not if your production prompts are working. But for new development or quality-improvement cycles, rebuild from a fresh baseline rather than patching legacy stacks — that's OpenAI's explicit recommendation.
Summary
GPT-5.5 prompting demands a shift from process-oriented to outcome-oriented design. OpenAI flags four legacy patterns — CoT nudges, overuse of absolute rules, heavy role-play scaffolding, and micro-managed process — as no longer load-bearing for many tasks. Business+IT adds "just-in-case" few-shot dumps to the same family. All of these remain appropriate when the procedure or examples are themselves the requirement.
OpenAI's replacement is the 7-element structure (Role / Personality / Goal / Success Criteria / Constraints / Output / Stop Rules) combined with a fresh-baseline migration strategy. The mindset change: define what to achieve, not how to think.
At ZenChAIne, we're applying this transition across our internal agents and client implementations, and we'll continue sharing what we learn along the way.